Pyacc jest narzędziem, które pozwala narzucić i kontrolować strukturę wejścia dla potrzeb różnego rodzaju programów komputerowych. Użytkownik pyacc-a przygotowuje specyfikację określającą jak powinno wyglądać wyjście. Sercem specyfikacji są reguły opisujące strukturę wejścia.
Pyacc generuje funkcję analizatora składniowego, która wywołuje dostarczoną przez użytkownika funkcję analizatora leksykalnego do obsługi wejścia na niższym poziomie. Analizator leksykalny znajduje w strumieniu wejściowym podstawowe jednostki leksykalne zwane tokenami. Tokeny są dopasowywane do reguł opisujących strukturę wejścia, zwanych regułami gramatycznymi. Gdy wejście zostanie dopasowane, wykonywany jest kod dostarczony przez użytkownika dla danej reguły gramatycznej, zwany akcją.
Pyacc jest generatorem analizatorów składniowych (parserów) typu LALR.
Za pomocą pyacc-a można stworzyć parser w sposób pokazany na rysunku:
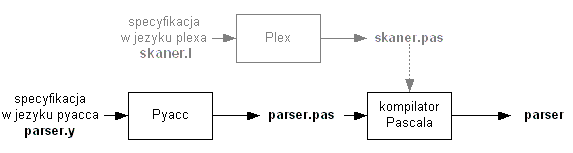
Uwaga: Wygenerowany przez pyacc-a parser wymaga podania kodu skanera. Najczęściej kod skanera jest generowany przy pomocy plex-a i dołączany do kodu parsera na etapie kompilacji. Kod skanera może być też utworzony przez programistę i umieszczony bezpośrednio w specyfikacji pyacc-a.
Specyfikacja dla pyacc-a ma następujący układ:
{deklaracje}
%%
{reguły}
%%
{procedury}
W sekcji deklaracje pomiędzy znakami %{ i %} umieszczany jest kod w języku Pascal, który ma być wstawiony bezpośrednio na początku generowanego programu, np.
%{
uses YaccLib, LexLib;
%}
Następnie znajdują się deklaracje symboli otrzymywanych od analizatora leksykalnego, zwanych tokenami. Nazwy używanych symboli leksykalnych są deklarowane w następujący sposób:
%token NAZWA1
%token NAZWA2
%token NAZWA3
i zwyczajowo pisane sa duzymi literami.
Dla każdego symbolu terminalnego lub nietermianlnego może być osobno określony typ. Powiązanie typu symbolu jest powiązane delkaracją symbolu i wygląda następująco:
%token <Real> NAZWA_TOKENU
w znaki < oraz > ujęta jest nazwa typu związanego
z symbolem (w powyższym przykładzie jest to typ Real).
W przypadku symboli nieterminalnych powiązanie ich z typami przyjmuje postać:
%type <Real> nieterminal1 %type <Char> nieterminal2
W tej sekcji umieszczamy reguły gramatyczne.
Ogólna postać reguły jest następująca:
<lewa strona> : <alternatywa 1> {akcja 1}
| <alternatywa 2> {akcja 2}
...
| <alternatywa n> {akcja n}
;
Przykładowo produkcje, które zapisywaliśmy jako:
E --> E + T | T
T --> 0 | ... | 9
w pyacc-u można zapisać jako:
wyr : wyr '+' term
| term
;
term : CYFRA
;
Symbole terminalne mogą być dwojakiego rodzaju:
%token TERMINAL_NAME; zwyczajowo identyfikatory terminali pisane są dużymi
literami,
Nazwa niezadeklarowana jako token, traktowna jest jako symbol nieterminalny. Każdy z symboli nieterminalnych musi przynajmniej raz pojawić się po lewej stronie reguły.
Domyślnie zakłada się, że symbolem początkowym gramatyki jest lewa strona pierwszej reguły. (Symbol początkowy gramatyki można zdefiniować jawnie w sekcji deklaracji w postaci %start symbol).
Z każdą regułą skojarzona może być akcja semantyczna. Akcja jest sekwencją instrukcji w Pascalu zawartą wewnątrz znaków nawiasów
{ i }. Akcja jest wykonywana w momencie, gdy parser rozpozna na wejściu strukturę, która została określona w regule. Akcja można definiowana także w środku definicji reguł.
Akcje mogą zwracać wartości i korzystać z wartości zwróconych przez inne akcje. Do tego celu wykorzystuje się zmienne $$,
$1, $2, $3...
Zmienna $$ przechowuje wartość zwracaną przez akcję. Zaś zmienne $1, $2, $3...
przechowują wartości odpowiadające kolejnym składnikom reguły, np.
wyr : wyr '+' term { $$ = $1 + $3 }
/*
$$ oznacza wartość zwracaną przez akcję,
$1 oznacza wartość skojarzoną z symbolem wyr (po prawej stronie produkcji),
$3 oznacza wartość skojarzoną z symbolem term,
podstawienie $$ = $1 + $3 spowoduje, że akcja zwróci wartość będącą sumą
wartości skojarzonych ze składnikami 1 i 3
*/
Jeżeli nie zdefiniowano inaczej domyślnie wartością reguły staje się wartość pierwszego składnika ($1) tj.
A : B {$$ = $1}; oznacza to samo co A : B ;
Domyślnym typem wartości semantycznych jest Integer. Można zmienić domyślne ustawienia wpisując sekcji deklaracji odpowiednio:
%{
type YYSType = Char;
%}
Użytkownik musi dostarczyć pyacc-owi analizator leksykalny odpowiedzialny za bezpośrednie kontrolowanie wejścia i dostarczanie symboli
terminalnych do parsera. Taka funkcję można wygenerować przy pomocy plex-a lub napisac wlasnoręcznie. Analizator leksykalny musi być
funkcją zwracającą Integer i mieć nazwę yylex.
function yylex : Integer;
Skaner ma za zadanie zwracać numer symbolu przeczytanego z wejścia.
Wartość atrybutu dla danego symbolu leksykalnego dostarczana jest parserowi poprzez predefiniowaną zmienną yylval.
Wewnątrz sekcji procedury pomocnicze często umieszczane są procedury obsługi błędów.
Uwaga: Komantarze mogą być umieszczone w dowolnym miejscu specyfikacji i są zawarte między znakami /* i */, np. /* komentarz */.
Uwaga:Składnia pliku generatora pyacc jest opisana szczegółowo wraz z przykładami w dokumentacji programu pyacc.
Poniżej znajduje się kod parsera, który oblicza wartość wyrażeń arytmetycznych złożonych z liczb całkowitych i znaków dodawania.
/* add.y
Obliczanie sumy.
Parser czyta z wejscia wyrazenia arytmetyczne zlozone z liczb calkowite i znakow '+',
na wyjsciu wypisuje wynik dodawania.
*/
%{
uses YaccLib, LexLib;
%}
%token NUM
%%
input :
| input '\n'
| input expr '\n' { writeln($2); }
;
expr : expr '+' NUM { $$ := $1 + $3;}
| NUM
;
%%
{$I addlex.pas}
begin
yyparse;
end.
Źródła: add.y
%{
(* addlex.l
Skaner wspolpracujacy z parserem add.y *)
%}
%%
[0-9] begin
val(yytext, yylval);
return(NUM);
end;
. |
\n returnc(yytext[1]);
Źródła: addlex.l
Przygotowujemy plik ze specyfikacją pyacc-a, np. example.y. Następnie przekształcamy specyfikację na program pascalowy
example.pas przy pomocy polecenia:
pyacc example.y
Jeżeli potrzeba, przygotowujemy plik ze specyfikacją plex-a, np. examplelex.l i generujemy kod skanera examplelex.pas
poleceniem:
plex examplelex.l
Kompilujemy wygenerowany kod parsera poleceniem:
ppc386 -Sg example.pas
Otrzymujemy program wynikowy example. Możemy go uruchomić przykładowo podając na wejście plik test_parser:
./example <test_parser
Poniżej umieszczony jest przykład specyfikacji pyacc-a dla parsera uproszczonej gramatyki wyrażeń arytmetycznych. Parser czyta z wejścia wyrażenia arytmetyczne złożone z liczb, operatorów + - * / oraz nawiasów i wypisuje na wyjście wyniki obliczeń.
/* expr.y
Parsera uproszczonej gramatyki wyrażeń arytmetycznych. Czyta z wejscia
wyrazenia arytmetyczne zlozone z liczb, operatorów + - * / oraz nawiasów
i wypisuje na wyjscie wyniki obliczeń.
*/
%{
uses YaccLib, LexLib;
%}
%token NUM
%%
input : /* empty */
| input '\n' { yyaccept; }
| input expr '\n' { writeln($2); }
;
expr : expr '+' term { $$ := $1 + $3; }
| expr '-' term { $$ := $1 - $3; }
| term
;
term : term '*' fact { $$ := $1 * $3; }
| term '/' fact { $$ := $1 div $3; }
| fact
;
fact : '(' expr ')' { $$ := $2; }
| NUM
;
%%
{$I exprlex.pas}
begin
yyparse;
end.
Źródła: expr.y
%{
(* exprlex.l
Skaner wspolpracujacy z parserem expr.y. *)
%}
%%
[0-9]+ begin
val(yytext, yylval);
return(NUM)
end;
" " ;
. |
\n returnc(yytext[1]);
Źródła: exprlex.l
Poniżej znajduje się kod najprostszego parsera ilustrujący przedefiniowanie domyślnego typu tokenu z Integer na Char.
/* char.y
Najprostszy parser ilustrujacy przedefiniowanie domyslnego typu tokenu z Integer na Char
*/
%{
uses YaccLib, LexLib;
type YYSType = Char;
%}
%token T_CHAR
%%
input :
| input '\n' { yyaccept; }
| input znaki '\n'
;
znaki : znaki T_CHAR { writeln('Znaleziono: ', $1); }
| T_CHAR { writeln('Znaleziono: ', $1); }
;
%%
{$I charlex.pas}
begin
yyparse;
end.
Źródła: char.y
%{
(* charlex.l
skaner wspolpracujacy z parserem char.y *)
%}
%%
[a-zA-Z] begin
yylval := yytext[1];
return(T_CHAR);
end;
. |
\n returnc(yytext[1]);
Źródła: charlex.l
Przeanalizować, skompilować i uruchmić przykłady przedstawione na tej stronie.
Napisać Makefile, który ułatwia tworzenie parserów z wykorzystaniem pyacc-a i plex-a.
Proszę napisać parser, który rozpoznaje poprawne wywołania kompilatora gcc w postaci:
gcc nazwa_pliku1.c [nazwa_pliku2.c ...]
Zakładamy, że nazwa pliku składa się z liter i cyfr.
Rozszerzyc parser z poprzedniego zadania o mozliwosc rozpoznawania opcji:
-o pliku_wyn
Przykłady:
| Wywołanie | Rezultat |
|---|---|
gcc | err |
gcc plik.c | ok |
gcc plik1.c plik2.c | ok |
gcc -o plik_wyn plik.c | ok |
gcc -o plik_wyn plik1.c plik2.c | ok |